デジタル庁は3月6日、政府業務で生成AIを活用する「ガバメントAI」の取り組みを発表した。政府向けAI基盤で試用する国産の大規模言語モデル(LLM:Large Language Model)7件を選定するとともに、全府省庁の政府職員約18万人を対象にした大規模実証を2026年度に開始する。
国産AIの公募、15件から7モデルを選定
デジタル庁は、政府AI基盤で利用する国産の大規模言語モデル(LLM)について公募を実施。国内企業・研究機関などから15件の応募があり、審査の結果、7件のモデルを選定した。
選定されたのは以下のモデル。
NTTデータ「tsuzumi 2」
KDDI/ELYZA「Llama-3.1-ELYZA-JP-70B」
ソフトバンク「Sarashina2 mini」
NEC「cotomi v3」
富士通「Takane 32B」
Preferred Networks「PLaMo 2.0 Prime」
カスタマークラウド「CC Gov-LLM」
これらのモデルは政府のAI利用基盤上で試験的に活用され、行政実務での有効性や課題などを検証する。
全府省庁の職員約18万人で実証
今回の取り組みでは、デジタル庁全職員が利用できる生成AIの利用環境「源内(げんない)」を用いた大規模実証を実施する。対象は全府省庁39機関の政府職員約18万人で、2026年5月から2027年3月までの期間で検証を進める予定だ。
この実証では、行政文書作成や政策調査、国会答弁の作成支援など、政府業務におけるAI活用の可能性を検証する。また各府省庁はAI統括責任者(CAIO:Chief AI Officer)によるガバナンス・統括監理を行い、実証結果を踏まえ、2027年度以降の本格導入や調達の可否を検討する方針としている。
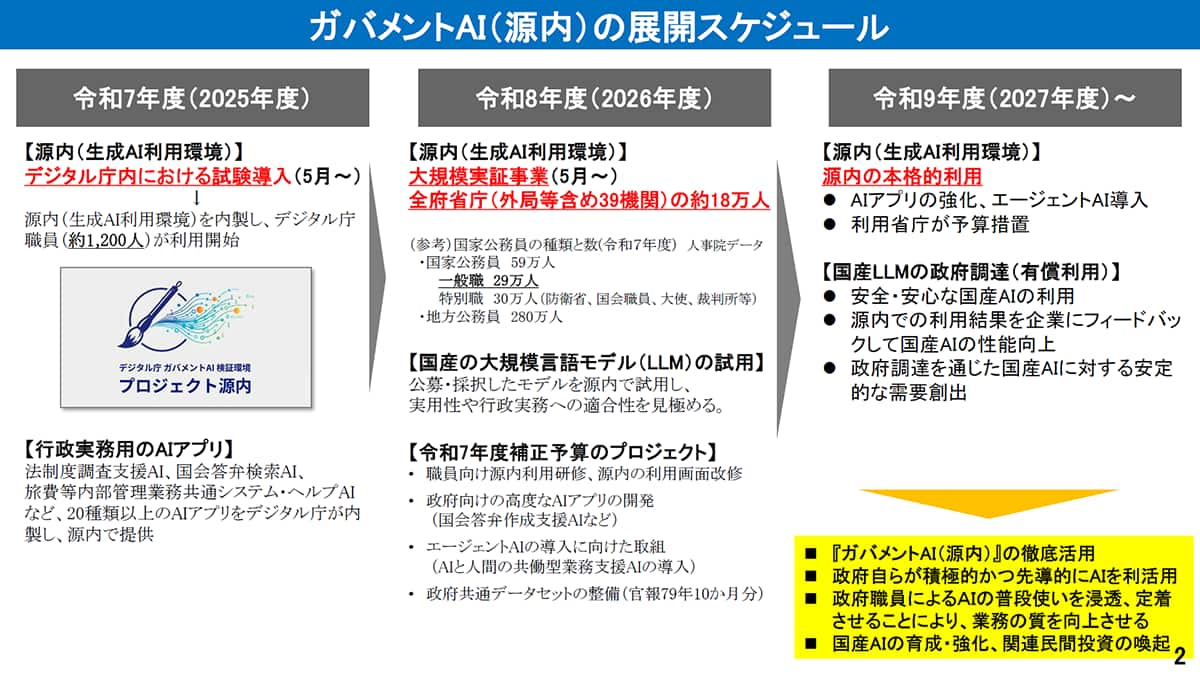
デジタル庁「今後のガバメントAI 源内の展開」より
行政DXと国産AI育成を同時に推進
ガバメントAIは、日本語特有の語彙・表現や法令文書に適したAIの活用を進めるとともに、機密情報を安全に扱える環境での運用を前提とする取り組みだ。政府は行政業務の効率化と同時に、国産AI産業の育成にもつなげたい考えだ。

源内を活用した国会答弁の作成のイメージ
デジタル庁は今回の実証を通じて、政府職員によるAIの活用を広げるとともに、行政業務の質と生産性の向上を目指すとしている。また国産AIの育成・強化を推進し、関連分野の民間投資を喚起しつつ、AIに関する日本の自律性確保の実現を促す。



























